Uruchomienie własnej strony lub bloga w 2024 roku nie jest zbyt trudne. Są gotowe serwisy, często darmowe,
można też wykupić hosting i zastosować jeden z popularnych systemów typu CMS. Jest też inna droga, czyli
odpalić generator stron statycznych, nie mówiąc już o oldskulowym utrzymywaniu tuzinów plików HTML. Kolejna
sprawa, gdzie udostępnić swoje dzieło? Tutaj też jest kilka możliwości, od usługi typu SaaS po tradycyjne
hostingi. Ja wybrałem Pelicana jako statyczny generator stron oraz GitLab Pages jako bezpłatny hosting.
Zanim się zabrałem za pisanie tego wpisu, przypomniał mi się taki obrazek:  Źródło: Komiks Honestly
Undefined #19, Rachim Dawlietkaliiew
Źródło: Komiks Honestly
Undefined #19, Rachim Dawlietkaliiew
Trudno nie znaleźć tutaj pewnej korelacji do mojej strony, bo sam wielokrotnie zmieniałem zdanie co do użytego
narzędzia. Wiele z tych prób nie opuściło, na szczęście, mojego komputera. Ostatecznie, nie jestem oryginalny
i postanowiłem opisać, jak to wszystko zgrałem. Chociaż zawsze mogło być gorzej i mogłem zacząć tworzyć własny
generator :-).
Założenia
Ilość dostępnych generatorów stron statycznych jest przytłaczająca. Przykładowo, na stronie
https://jamstack.org/generators/ możemy znaleźć ponad 350 propozycji do
wykorzystania (stan na dzień publikacji wpisu). Trudno więc znaleźć ten idealny i, na pewno, mój obecny wybór
taki nie jest. Żeby nie utonąć w tym urodzaju, ułożyłem takie kryteria:
Brak zależności od JS-u — JavaScript, czy ściślej ECMAScript, w połączeniu z bibliotekami, czy
frameworkami jest potężną platformą programistyczną. Jednocześnie uważam, że do prostych stron, jak ten blog,
doskonale poradzi sobie sam HTML i CSS. Taka strona szybko się załaduje, łatwo cache'uje i indeksuje.
Wsparcie wielojęzyczności — nawet jeśli teraz wszystkie wpisy będą powstawać po polsku, nie wykluczam, że
część treści będę tłumaczył na język angielski. Opcjonalnie chciałbym mieć możliwość powołania osobnej
podstrony językowej po angielsku.
Automatyzacja publikacji — w przypadku tzw. DevOpsa, to nie powinno chyba dziwić, że chciałbym, żeby
całość trzymać w repozytorium Git oraz traktować merge na gałąź main jako publikację.
Niskie koszty — statyczna strona powinna być tania w utrzymaniu, a, jak to mówi mistrz Walaszek:

Statyczny generator, który spełnił moje kryteria to Pelican. Strony, które generuje,
są czystymi plikami HTML i CSS, a resztę wodotrysków można zaprogramować na poziomie szablonów. Strony są
generowane wykorzystując popularny system szablonów Jinja2. Muszę
przyznać, że wybór był tutaj spory i postawiłem na rozwiązanie napisane w Pythonie, w którym na co dzień piszę
potrzebne mi skrypty. Z wyborem hostingu było łatwiej, gdyż swoje projekty związane z kodem trzymam
najczęściej na GitLabie, więc naturalną drogą było pójście w stronę lubianego przeze mnie GitLab CI oraz
usługi GitLab Pages. Spełnia to argument niskich kosztów, gdyż jedyny koszt, jaki tutaj muszę ponieść, to
roczny koszt domeny, którą cały czas opłacam.
Przygotowanie środowiska
Na początek przygotowałem środowisko pracy. Pelican jest napisany w Pythonie, zatem potrzebny będzie
interpreter tego języka w systemie. Na Windowsie wystarczy zainstalować najnowszą wersję Pythona z Microsoft
Store'a lub bezpośrednio ze strony Python.org. Korzystając z większości dystrybucji
Linuksa, interpreter Pythona prawdopodobnie będziemy mieć już zainstalowany, bo część aplikacji go
wykorzystuje do działania. U mnie, na dystrybucji bazującej na Ubuntu 22.04 LTS (Tuxedo OS
3), zainstalowany jest Python 3.10. Domyślnie nie miałem zainstalowanego
menedżera pakietów pip. Na Ubuntu instalacja przebiega przez wydanie komend w konsoli:
sudo apt update # Odświeżenie stanu repozytoriów oprogramowania
sudo apt install python3-pip # Instalacja menedżera pakietów
Tradycyjnie moglibyśmy teraz zainstalować pakiet pelican używając zainstalowanego przed chwilą
pip-a. Niestety, domyślnie w Pythonie pakiety są instalowane w przestrzeni użytkownika, globalnie. To
znaczy, że wszystkie biblioteki, które zainstalujemy (oraz ich zależności) stają się dostępne cały
czas. Rzadko kiedy pracujemy tylko nad jednym projektem, więc może okazać się, że poszczególne biblioteki,
których używamy, wzajemnie się wykluczają. Ponadto, gdy chcemy udostępnić nasz projekt dalej, trudniej wtedy
wskazać, jakich zależności faktycznie nasz projekt wymaga. Dobrym rozwiązaniem jest skorzystanie z obecnego w
bibliotece standardowej Pythona, modułu venv.
Tworzy on odizolowane środowisko pracy dla naszego projektu, co rozwiązuje problem z, opisanym wyżej,
tzw. piekłem zależności (ang. dependency hell) w skali systemu. Użycie venv jest bardzo proste:
python3 -m venv .venv # Stworzenie środowiska w podfolderze .venv
source .venv/bin/activate # Aktywacja uruchomionego środowiska
Ja skorzystałem z dodatkowego narzędzia Pipenv, które automatyzuje
zarządzenie wirtualnymi środowiskami Pythona w systemie, a na dodatek dokładniej śledzi wersje wskazanych
zależności projektu. Tradycyjnie, do wskazania zależności aplikacji, wykorzystywany jest prosty plik tekstowy
requirements.txt, w którym zawarte są bezpośrednie wskazania bibliotek i ich wersji, a konkretna wersja
biblioteki jest zawsze określana w trakcie instalacji poleceniem pip install -r requirements.txt. Pipenv
rozszerza zarządzanie zależnościami do pliku definicji Pipfile, gdzie wskazujemy jakie pakiety i w jakim
zakresie wersji nasz projekt wymaga do poprawnej pracy. Jednocześnie, przy instalacji generowany jest plik
blokady Pipfile.lock, gdzie wskazane są hasze konkretnych wersji używanych pakietów. Ma to dwie zalety:
każdy członek zespołu ma zawsze dokładne te same wersje zależności aplikacji oraz, jeśli ktoś by podmienił
plik na repozytorium pakietów, suma kontrolna nie będzie się zgadzać i Pipenv zgłosi nam błąd. To dobre
zabezpieczenie przed atakami na łańcuch zależności (ang. supply chain), stosowane m.in. w menedżerze
pakietów npm.
Aby zainstalować Pipenva wystarczy wydać polecenie: pip install --user pipenv. Od tego momentu, powinniśmy
mieć dostępne polecenie pipenv. Jeśli terminal nam go nie znajduje, czasami wystarczy zrestartować terminal,
przelogować się lub, na Linuksie, sprawdzić, czy mamy ścieżkę ~/.local/bin w naszej zmiennej środowiskowej
PATH. Ostatecznie, zawsze możemy skorzystać z fortelu, wywołując ten moduł bezpośrednio z wywołania Pythona,
tj. python -m pipenv.
Utworzenie projektu
Mamy już wszystkie potrzebne narzędzia do utworzenia i skonfigurowania bloga. Stworzyłem więc folder
projektowy, zainstalowałem Pelicana w środowisku wirtualnym oraz skonfigurowałem szkielet mojego bloga. Przy
okazji doinstalowałem też obsługę języka znaczników Markdown. Domyślnie możemy korzystać tylko z
reStructuredText. Tutaj wygrywa u mnie osobista preferencja :-).
mkdir moj-blog
cd moj-blog
pipenv install "Pelican[markdown]"
pipenv shell
Po wykonaniu tych poleceń konsola wczyta nowe środowisko pracy, specjalnie dla nowego projektu. 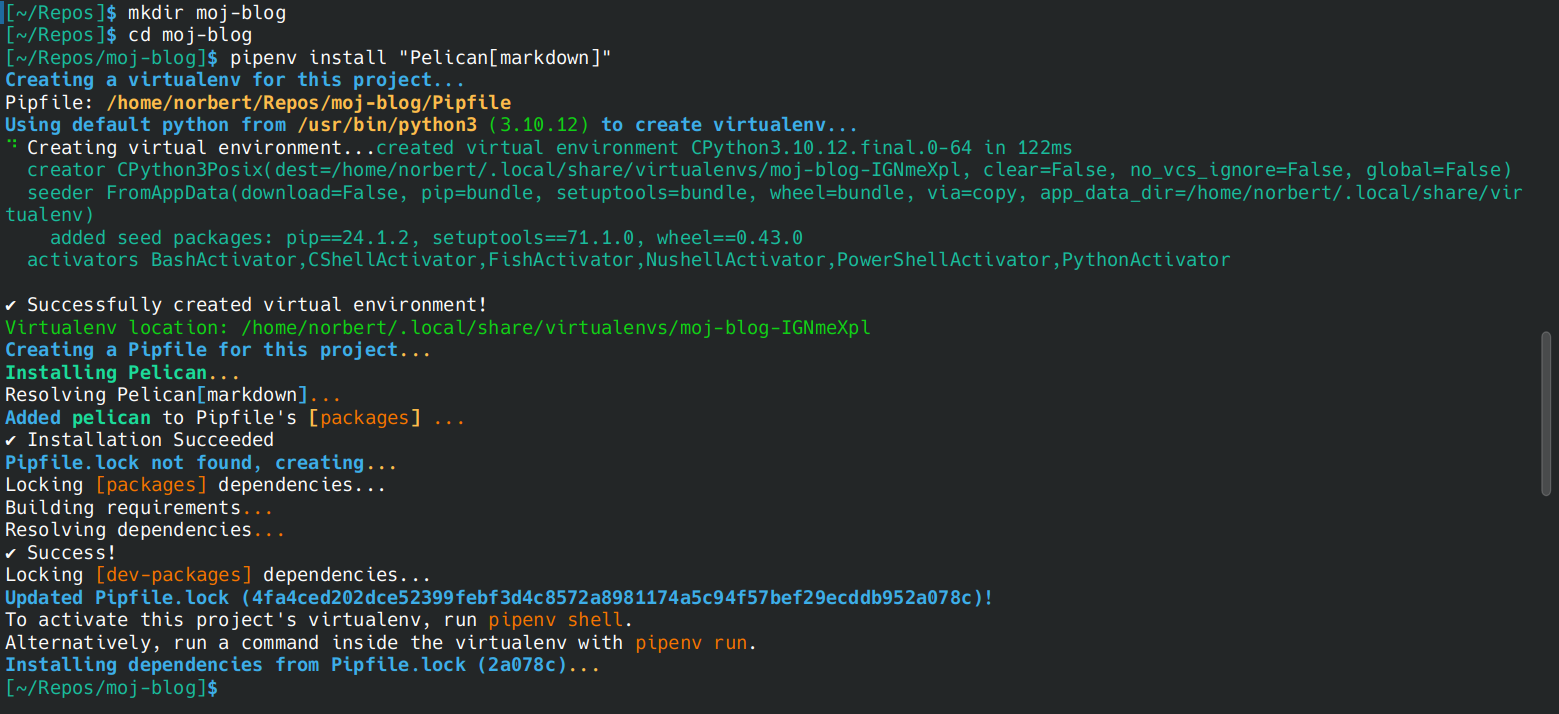
Czas wygenerować szkielet plików — służy do tego skrypt pelican-quickstart. Zadaje on kilka pytań, przede
wszystkim o tytuł bloga, głównego autora oraz docelowy adres URL, pod którym będzie dostępny.
[~/Repos/moj-blog]$ pelican-quickstart
Welcome to pelican-quickstart v4.9.1.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files
needed by Pelican.
Using project associated with current virtual environment. Will save to:
/home/norbitor/Repos/moj-blog
> What will be the title of this web site? /home/norbitor
> Who will be the author of this web site? Norbert Langner
> What will be the default language of this web site? [pl]
> Do you want to specify a URL prefix? e.g., https://example.com (Y/n)
> What is your URL prefix? (see above example; no trailing slash) https://www.norbitor.net.pl
> Do you want to enable article pagination? (Y/n)
> How many articles per page do you want? [10]
> What is your time zone? [Europe/Rome] Europe/Warsaw
> Do you want to generate a tasks.py/Makefile to automate generation and publishing? (Y/n) n
Done. Your new project is available at /home/norbitor/Repos/moj-blog
W tym momencie mamy już gotowy do działania blog. Żeby zobaczyć efekt naszej pracy, wystarczy uruchomić serwer
deweloperski poleceniem pelican --listen --autoreload i otworzyć adres
http://127.0.0.1:8080 w naszej ulubionej przeglądarce.
Pierwszy post
Na razie jest tu dosyć pusto, czas więc napisać tradycyjnego „Hello Worlda”. Na początek będę bazował na
domyślnej strukturze katalogów. Z czasem, możemy wykorzystać możliwości konfiguracyjne Pelicana,
dostosowując niektóre ustawienia do swoich preferencji. Treść dodajemy poprzez tworzenie plików w podfolderze
content. Warto od razu utworzyć w nim podfolder images, aby pozbyć się jednego ostrzeżenia podczas
generowania strony. Plik ze wpisem może znajdować się bezpośrednio w folderze content, ale możemy
organizować nasze treści w podkatalogach. Nie ma to jednak domyślnie wpływu na to, pod jakim adresem dostępny
będzie wpis. Stworzyłem teraz wstępną wersję wpisu hello-world.md i wypełniłem go treścią.
Title: Hello World
Date: 2024-08-21 17:59
Category: Różne
Tags: powitanie, blog, wstęp
Slug: hello-world
Witaj, Świecie!
Jeśli wcześniej nie zamknęliśmy serwera deweloperskiego, to możemy po prostu odświeżyć stronę w przeglądarce,
żeby zobaczyć nowy wpis. W ogólności, pierwsze linie pliku zawierają metadane wpisu, przedstawione powyżej to
rozsądne minimum. Treść wpisu oddzielona jest od nagłówka pustą linią — tu zaczyna się standardowy dokument w
Markdownie. Po dokładniejszy opis sposobu tworzenia i opisywania treści odsyłam do rozdziału „Writing
Content” dokumentacji Pelicana.

Konfiguracja strony
Domyślna konfiguracja strony jest całkiem w porządku, ale możemy już zauważyć, że stopka strony jest
wypełniona jakimiś linkami. Wypadałoby podmienić je na swoje. Możemy to zrobić edytując plik pelicanconf.py,
który zawiera główną konfigurację naszej strony — zarówno Pelicana, jak i używanego szablonu oraz
wtyczek. Wspomniane przeze mnie ustawienia, zdefiniowane są w zmiennych LINKS oraz SOCIAL. Wrzuciłem tam
linki do mojej strony-wizytówki oraz garstki innych stron z pogranicza
social media (np. konto na GitLabie). Oprócz tego moją stronę wdrożyłem na usłudze Gitlab Pages, która
wymaga, aby publikowane pliki znajdowały się w folderze public. Dodatkowo zmieniłem nieco format daty oraz
docelową ścieżkę wygenerowanych stron. Ostatecznie chciałbym pisać moim blogu też po angielsku, dlatego taka
zmiana. Poniżej zamieszczam zmienione i dodane przeze mnie wartości (oprócz linków).
OUTPUT_PATH = 'public/'
DATE_FORMATS = {
'pl': ('pl_PL.utf8', '%d.%m.%Y'),
'en': ('en_US.utf8', '%m/%d/%Y'),
}
ARTICLE_URL = '{lang}/{date:%Y}/{date:%m}/{slug}.html'
ARTICLE_LANG_URL = ARTICLE_LANG_SAVE_AS = ARTICLE_SAVE_AS = ARTICLE_URL
Listę ustawień generatora możemy, standardowo, znaleźć w dokumentacji
Pelicana. Każdy szablon może korzystać z własnych
wartości, więc należy zerknąć do opisu (bo czasem trudno to nazwać dokumentacją) używanego szablonu. Na tym
etapie wystarczy zacząć pisać, w moim przypadku, ten wpis.
Oprócz powyższego jest jeszcze plik publishconf.py, który pozwala na nadpisanie niektórych ustawień, jeśli w
wariancie produkcyjnym chcemy, żeby były inne. Domyślnie, wariant produkcyjny uruchamia generowanie plików dla
czytników wiadomości oraz wskazuje dokładny adres URL, pod którą nasza strona będzie dostępna — wykorzystywane
jest to do generowania poprawnych linków do podstron i pozostałych plików.
GitLab CI oraz Pages
Nadszedł ten moment, aby opublikować efekty pracy. Klasycznie wygenerowałbym pliki HTML i wgrał przez FTP na
serwer. GitLab Pages działa nieco inaczej, więc musiałem przygotować pipeline budujący stronę przy użyciu
GitLab CI. Jest to bardzo proste, wystarczy stworzyć plik .gitlab-ci.yml. Dla mojej strony cały Pipeline
wygląda następująco:
image: python:3.10-alpine
workflow:
rules:
- if: $CI_COMMIT_BRANCH
pages:
stage: deploy
variables:
PIPENV_VENV_IN_PROJECT: 1
script:
- pip install pipenv
- pipenv install --deploy
- pipenv run pelican -s publishconf.py
artifacts:
paths:
- public
cache:
paths:
- .venv/
rules:
- if: $CI_COMMIT_BRANCH == "main"
environment: production
Wskazałem obraz Pythona zgodny z tym, co mam na swoim komputerze, aby mieć pewność, że wszystko zadziała tak,
jak u mnie. Z czasem trzeba będzie nieco podbijać tę wersję. Pipeline ograniczyłem też do commitów
uruchomionych na gałęzi main, bo nie mam potrzeby uruchamiania wersji recenzenckich dla moich
wpisów. Względem typowej konfiguracji wykorzystuję tutaj pipenv, żeby nie musieć generować lokalnie pliku
requirements.txt, przy każdej zmianie w wykorzystywanych bibliotekach. Dla przyspieszenia budowania (GitLab
CI jest rozliczany minutowo), cache-uję sobie środowisko wirtualne, aby nie musieć za każdym razem pobierać
zależności od nowa. W razie potrzeby aktualizacja bibliotek zostanie wykonana.
Musiałem też stworzyć plik .gitignore, aby do repozytorium nie trafiały pliki tymczasowe edytora — w moim
przypadku Emacsa. Wykluczam też folder public, aby nie wrzucić przypadkiem roboczych plików HTML. Na ten
moment, nie miałem potrzeby dodawania wykluczeń dla innych plików, w tym tymczasowych plików środowiska
Pythona (np. pliki *.pyc), ale wraz z rozwojem strony pewnie będę musiał. Lubię jednak nie wrzucać
wszystkiego na zapas, żeby niepotrzebnie nie zaśmiecać repozytorium.
# Ignore temporary files
\#*\#
*~
# Ignore output directory
public/
To w zasadzie tyle. Wystarczy teraz zainicjować nowe repozytorium w folderze ze stroną, zrobić pierwszy
commit, założyć repozytorium na GitLabie oraz wypchnąć swoje dzieło. Strona zostanie automatycznie
zbudowana i opublikowana pod półlosowym adresem. Dokładny opis możliwości znajduje się w dokumentacji GitLab
Pages, podpowiem tylko, że
najważniejsza jest nazwa naszego użytkownika. Ja, z racji posiadanej domeny, dodałem własną domenę. Na stronie
projektu na GitLabie, w zakładce Deploy -> Pages jest opcja, która na to pozwala.
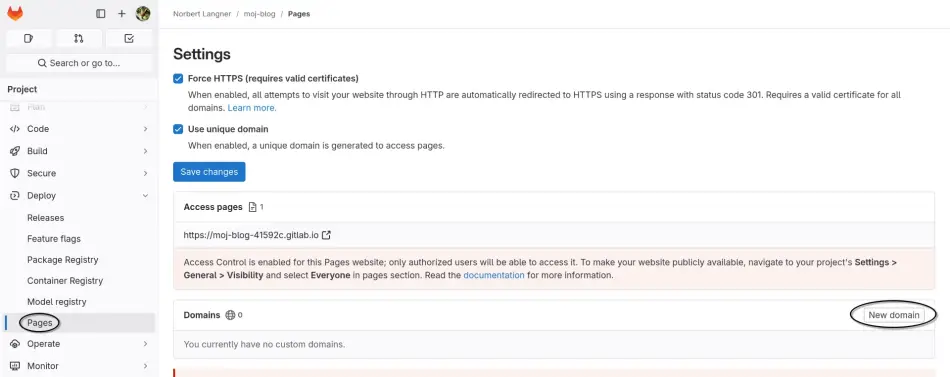
Trzeba pamiętać o dodaniu wpisów do DNS-a. Jako rekord CNAME dla naszej docelowej (sub)domeny podajemy
domenę wygenerowaną przez GitLaba. I to wszystko, strona po chwili będzie widoczna pod wskazanym adresem.
Podsumowanie
Stworzenie i opublikowanie prostego bloga przy użyciu Pelicana to zadanie na jeden wieczór. Dużo więcej
czasu spędziłem na napisanie tego wpisu, niż na faktyczne uruchomienie strony. Dokumentowanie nie jest łatwe,
jak widać :-). W dalszej perspektywie będę pracował nad rozwojem technicznym tej stronki, a wszystkie przygody
postaram się skrzętnie opisywać na łamach tego bloga.
Kod źródłowy strony jest otwarty i dostępny jako projekt na
GitLabie do wglądu. Kod i konfigurację udostępniam na licencji
BSD-3-Clause, treść na CC-BY-ND, własne obrazki, ryciny zaś na CC-BY. Opiszę to dokładnie na osobnej
podstronie tego bloga, bo wymaga to nieco wyjaśnienia :-).
Niedługo też postaram się zaimportować tutaj moją archiwalną serię wpisów na temat praktyk zawodowych, które
odbyłem w technikum. Nadal do mnie to nie chce dotrzeć, ale było to 11 lat (sic!) temu.